Designing a hybrid AI/ML data access strategy using Amazon SageMaker

Over time, many businesses have built a local server cluster, gathering data and then acquiring more servers and storage. They often start their ML adventure by experimenting locally on their laptops. Artificial intelligence (AI) investment is at a different stage in each business organization. Some remain entirely local, others are hybrid (both local and in the cloud), and others have moved entirely to the cloud to support AI and machine learning (ML) workloads.
These companies are also exploring or have begun to use the cloud to augment their local systems for several reasons. As technology grows over time, the size and volume of data increases. The amount of data captured and the number of data points continues to grow, presenting challenges for local management. Many businesses are dispersed, with offices in different geographies, continents, and time zones. While it is possible to increase the footprint locally, maintenance and upkeep costs are still hidden. These organizations are looking to the cloud to shift some of these efforts and enable them to rip and use the rich artificial intelligence and machine learning features in the cloud.
Defining a hybrid data access strategy
Moving machine learning workloads to the cloud requires a reliable hybrid data strategy that describes how and when to connect local data stores to the cloud. For the moment, it makes sense for the cloud to be the source of truth while allowing teams to use and manage data sets locally. Defining the cloud as the source of truth for data sets means that the original copy will reside in the cloud, and each data set generated will be stored in the exact location in the cloud. This ensures that data requests are served from the primary and derived copies.
A hybrid data access strategy should consider the following points.
Know and understand your current and future storage for ML on-premises. Create an ML workload map with performance and access requirements for testing and training. Define connectivity across local and cloud locations. This includes east-west and north-south traffic to support interconnection between locations and the required bandwidth and capacity for data transfer workloads. Define your single source of truth (SSOT)[1] and identify where the ML datasets will primarily reside. Consider how obsolete, new, hot, and 'cold data' will be stored. Define your storage performance requirements by mapping them to appropriate cloud storage services. This will allow you to use native machine learning in the cloud with Amazon SageMaker.
Hybrid data access strategy architecture
To help address these challenges, the developers have worked to present a comprehensive system architecture in Figure 1 that defines 1) Connectivity between local data centers and AWS regions, 2) Mapping local data to the cloud, and 3) Aligning Amazon SageMaker with appropriate storage, based on ML requirements.
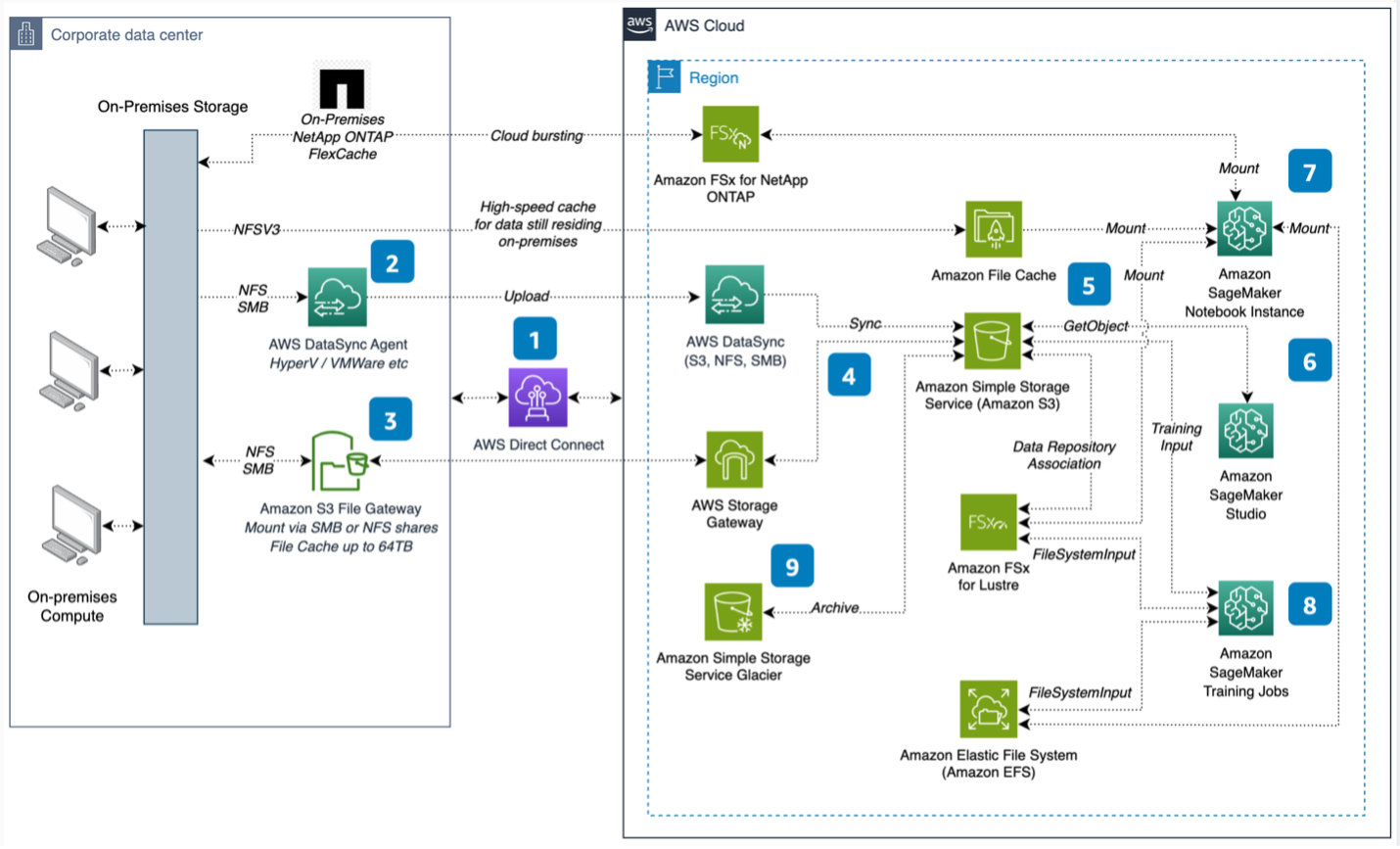
It is time to take a step-by-step look at this architecture.
- Local connectivity to the AWS Cloud is done via AWS Direct Connect for high transfer speeds.
- AWS DataSync migrates large data sets to Amazon Simple Storage Service (Amazon S3). The AWS DataSync agent is installed locally.
- Local network file system (NFS) or server message block (SMB) data is connected to the cloud via the Amazon S3 File Gateway, using a virtual machine (VM) or hardware device.
- The AWS Storage Gateway uploads the data to Amazon S3 and stores it in a local cache.
- Amazon S3 is the source of truth for ML resources stored in the cloud.
- Download S3 data for experimentation to Amazon SageMaker Studio.
- Amazon SageMaker notebook instances can access data via S3, Amazon FSx for Luster, and Amazon Elastic File System. Use Amazon File Cache for fast caching to access local data and Amazon FSx for NetApp ONTAP for cloud data transfer.
- SageMaker training tasks can use data in Amazon S3, EFS and FSx for Lustre. S3 data can be accessed via File, Quick File or Pipeline mode and is preloaded or loaded with a delay when using FSx for Lustre as the training task input. Any existing ESF data can also be made available for training.
- Use Amazon S3 Glacier to archive data and reduce storage costs.
ML workloads using Amazon SageMaker
Take a closer look at how SageMaker can help you with ML workloads.
To map ML workloads to the cloud, consider which AWS storage services work with Amazon SageMaker. Amazon S3 typically serves as a central storage location for both structured and unstructured data used for machine learning. This includes raw data from the parent applications as well as selected data sets that are organized and stored within the feature store.
In the initial development phase, SageMaker Studio users will use the S3 APIs to download data from S3 to their private home directory. This home directory is backed by the EFS file system managed by SageMaker. Studio users then direct their notepad code (stored in the home directory) to the local dataset and begin their development tasks.
SageMaker users can run training tasks outside the SageMaker Studio notebook environment to scale up and automate model training. There are several options for sharing data for a SageMaker training task.
Amazon S3. Users can specify the S3 location of the training data set. When using S3 as a data source, there are three data entry modes:
- File mode. This is the default input mode, where SageMaker copies data from S3 to the training instance storage. This storage is an Amazon Elastic Block Store (Amazon EBS) volume provided by SageMaker or an NVMe SSD attached to specific instance types. Learning does not start until the data set is downloaded to the storage, and there must be enough space in the storage to accommodate the entire data set.
- Fast file mode. Fast file mode provides S3 objects as a POSIX file system in the training instance. The data set files are streamed from S3 on demand as the training script reads them. This means that training can start earlier and require less disk space. Fast file mode also requires no changes to the training code.
- Pipe mode. Pipe input also streams data in S3 when the training script reads it but requires changes to the code. The newer and easier-to-use Fast File mode has largely replaced pipe input mode.
FSx for Lustre. Users can specify the FSx for the Lustre file system that SageMaker will mount in the training instance and run the training code. When the FSx for the Lustre file system is connected to the S3 tray, data can be loaded from S3 during the first training job. Subsequent training tasks on the same dataset can be accessed with little delay. Users can also pre-load the file system with S3 data using hsm_restore commands.
Amazon EFS. Users can specify an EFS file system that already contains their training data. SageMaker will mount the file system in the training instance and run the training code.
Find out how to choose the best data source for your SageMaker training job.
Applications
With this reference architecture, you can develop and deliver machine learning workloads that run locally or in the cloud. Your enterprise can continue using local storage and computing power for specific ML workloads while using the cloud with Amazon SageMaker. The scale available in the cloud allows your business to experiment without worrying about capacity. Start defining your hybrid data strategy on AWS today!
Additional resources

44-200 Rybnik
Poland
REGON: 240692928
National Court Register (KRS): 275333


