Reduce archiving costs with serverless data archiving

For regulatory reasons, the decommissioning of core business systems in the financial services and insurance (FSI) markets requires data to remain available for many years after the application is decommissioned. Traditionally, FSI companies have either outsourced data archiving to third-party service providers who maintain application replicas or purchased vendor software to retrieve and visualize archived data.
Through this article, the authors aim to present a more cost-effective option for serverless data archiving on Amazon Web Services (AWS). In their experience, you can build your cloud solution on Amazon Simple Storage Service (Amazon S3) for a fifth of the price of third-party alternatives. If you are phasing out older core business systems, consider serverless archiving to reduce costs while maintaining compliance.
Serverless archiving and data recovery
Modern archiving solutions follow the principles of modern applications:
- Serverless first-party programming to reduce management costs.
- Cloud-native to leverage native AWS service capabilities, such as backup or disaster recovery, to avoid custom compilation.
- Consumption-based pricing, as archive data is consumed intermittently.
- Speed of delivery, as both deployment and archiving operations must be performed quickly to meet regulatory requirements.
- Flexible storage policies can be enforced in an automated manner.
- AWS Storage and Analytics services offer the building blocks for a modern, serverless archiving and retrieval solution.
Data archiving can be implemented on Amazon S3 and AWS Glue.
- Amazon S3 storage tiers enable different data storage policies and service level agreements (SLAs) for recovery. You can migrate data to Amazon S3 using AWS Database Migration Service; otherwise, consider another data transfer service such as AWS DataSync or AWS Snowball.
- AWS Glue crawlers automatically infer database schemas and tables from Amazon S3 data and store the associated metadata in the AWS Glue Data Catalog.
- Amazon CloudWatch monitors the execution of the AWS Glue crawlers and notifies of failures.
Figure 1 provides an overview of the solution.
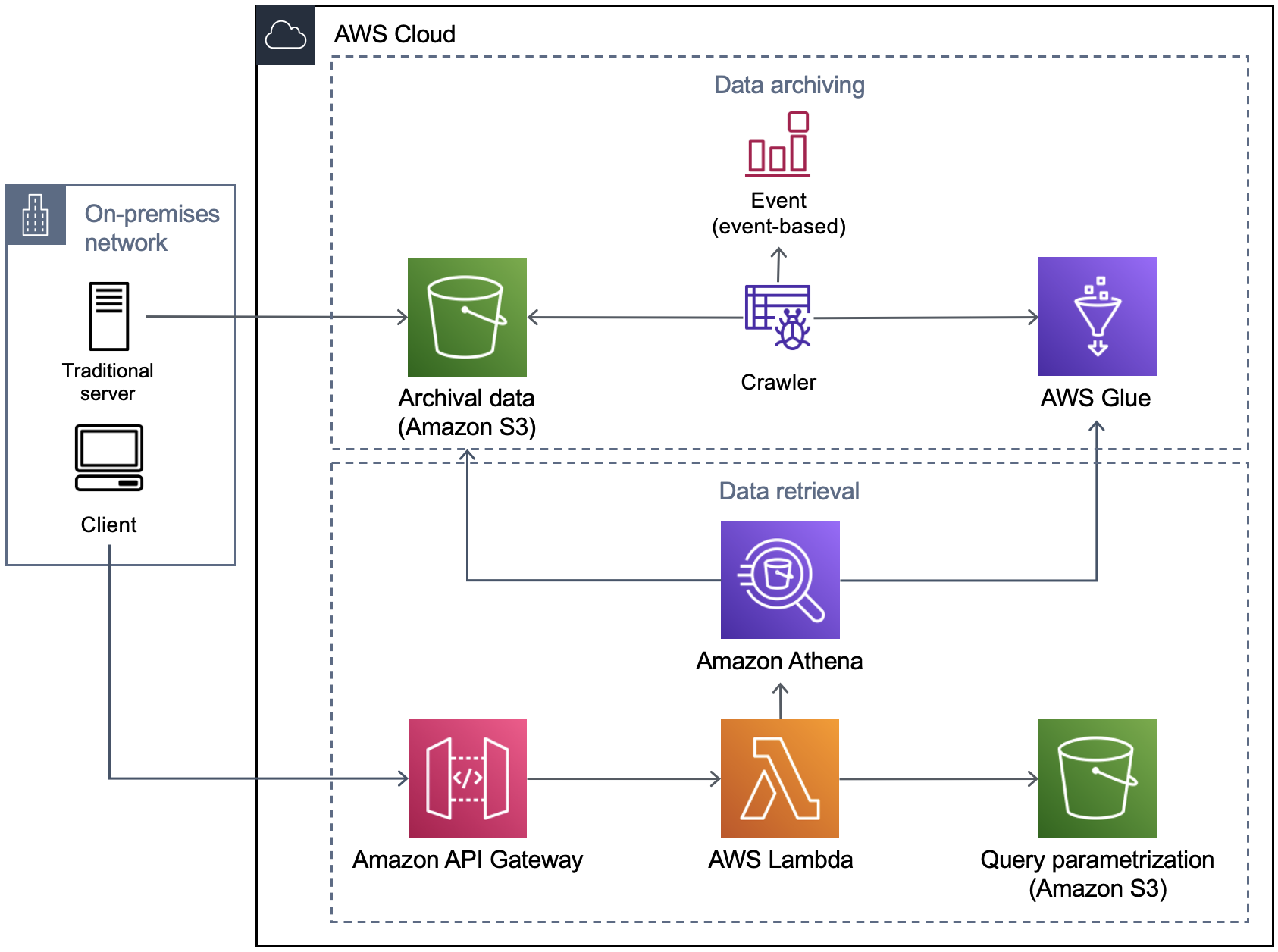
Once the archive data has been cataloged, Amazon Athena can use standard SQL for serverless data retrieval operations.
- Amazon API Gateway receives data retrieval requests and facilitates integration with other systems via REST, HTTPS or WebSocket.
- AWS Lambda reads data/parameterization templates from Amazon S3 to construct SQL queries. Alternatively, the query templates can be stored as key-value entries in a NoSQL shop like Amazon DynamoDB.
- Lambda functions trigger Athena with a constructed SQL query.
- Athena uses AWS Glue Data Catalog to retrieve table metadata for Amazon S3 (archive) data and return the SQL query results.
How the authors built serverless data archiving
An early 'build or buy' evaluation compared vendor products with custom solutions using Amazon S3, AWS Glue, and a user interface for data retrieval and visualization.
The total cost of ownership over 10 years for one core insurance system (Policy Admin System) was US$0.25m to build and run a custom solution on AWS, compared to more than US$1.1m for third-party alternatives. The cost advantage of implementing a custom solution was due to the efficiency of programming using AWS services. The lower cost of ownership was due to the less frequent use of archives and the fact that you pay only for what you use.
The data archiving solution was implemented with AWS services (Figure 2):
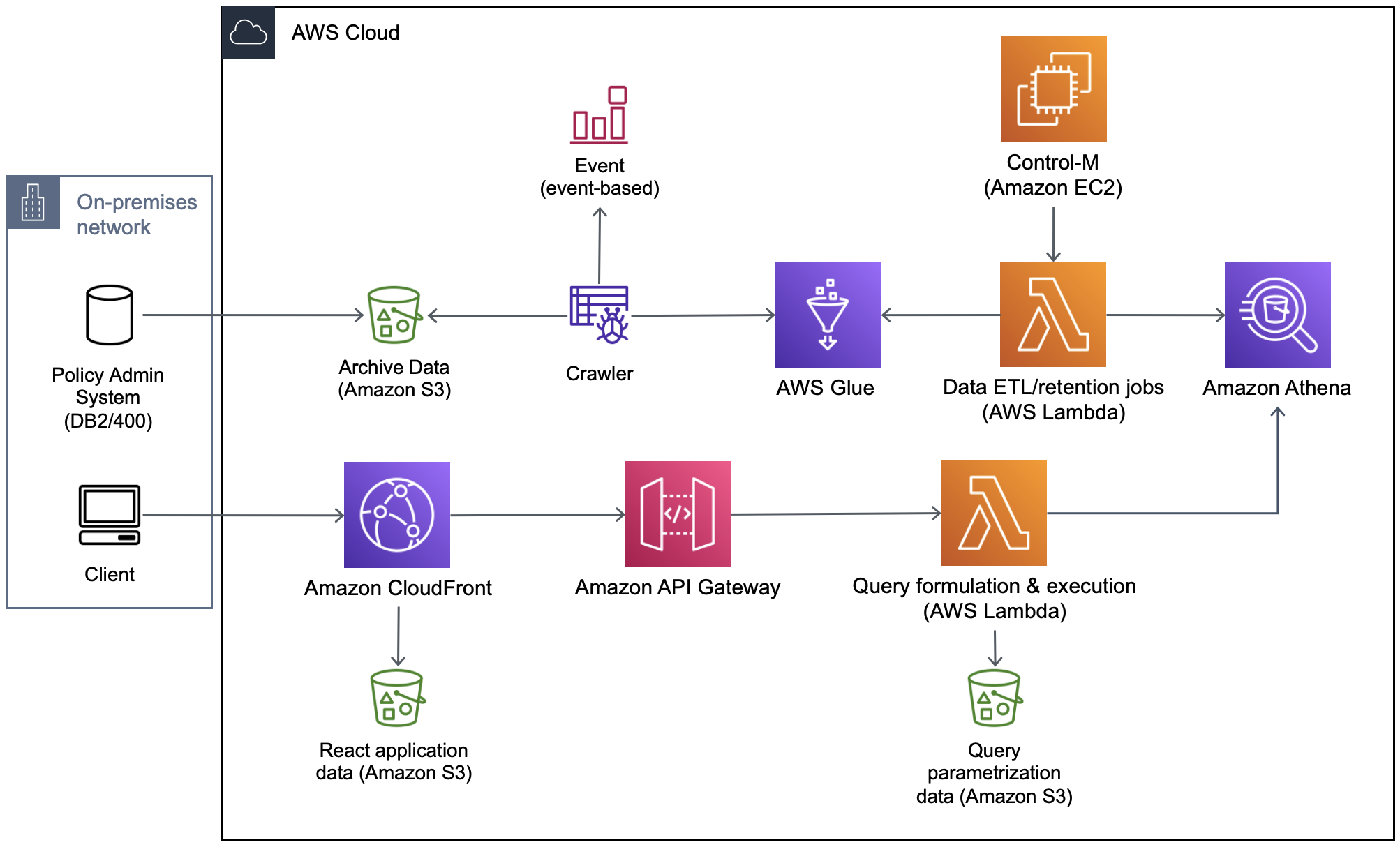
- Amazon S3 service captures archive data in Parquet format (optimized for analytics and compressed to reduce storage space), which is loaded from the underlying insurance system. The source of the archive data was an AS400/DB2 and transferred via Informatica Cloud to Amazon S3.
- AWS Glue crawlers infer the database schema from the objects in Amazon S3 and create tables in AWS Glue for the backed-up application data.
- Lambda functions (Python) delete data records based on the storage rules configured for each domain, such as customers, policies, claims, and receipts. A daily job (Control-M) initiates the retention process.
Retrieval operations are formulated and executed using Python functions in Lambda. The following AWS resources implement the download logic:
- Athena is used to run SQL queries on AWS Glue tables for the retracted application.
- Lambda functions (Python) build and execute queries to retrieve data. The functions render HMTL fragments using the Jinja template engine and Athena query results, returning the selected template populated with the requested archive data. Due to the separation of application layers, Using Jinja as the template engine has improved delivery speed and reduced cumbersome frontend and backend changes when modeling retrieval operations by ~30%. As a result, engineers only need to build an Athena query with a linked Jinja template.
- Amazon S3 stores the template configuration and the queries (JSON files) used to parameterize the queries.
- The Amazon API Gateway serves as a single entry point for API calls.
The user interface for data retrieval and visualization is implemented as a web application using the React JavaScript library (with static content on Amazon S3) and Amazon CloudFront for web content delivery.
The archiving solution enabled 80 use cases with 60 queries and reduced storage from three terabytes at the source to just 35 gigabytes at Amazon S3. The success of the implementation depended on the following key factors:
- Adequate sponsorship from the business in all areas (claims, compliance, etc.).
- Definition of SLAs to respond to courts, regulators, etc.
- Minimum viable and mandatory approach
- Early visualization of prototypes (quick failures)
Summary
Traditionally, FSI companies have relied on vendor products for data archiving. In this article, the authors explore how to build a scalable solution on Amazon S3 and discuss key implementation issues. They show that AWS services enable FSI companies to build a serverless archiving solution while achieving and maintaining compliance at a lower cost.

44-200 Rybnik
Poland
REGON: 240692928
National Court Register (KRS): 275333


